



Intel Sandy Bridge处理器抢先预览
四大进化助腾飞 Sandy Bridge架构深入解析
Intel宣称Sandy Bridge采用了全新设计的微架构,属于Tick-Tock发展策略中的Tock环节。

在旧金山秋季IDF 2010上,浦大卫对Sandy Bridge的技术架构进行了详细的解析。
不过从浦大卫先生的讲解来看,Sandy Bridge并不是彻底从零开发的革命性产品,本质上和现有架构仍有很多相同之处,但通过在以下四个方面的完善和增强,带来了性能上的明显进步。
1.整合物理寄存器堆 提升浮点运算能力
类似于AMD的推土机、山猫架构,Sandy Bridge也使用了物理寄存器堆(Physical Register File),这个功能块起的主要作用是节约功耗。所有微指令运算数据将存储在物理寄存器堆里,而无需带入乱序执行引擎里。当乱序执行引擎需要使用这些数据时,只需从微指令找到这些数据的对应指针即可。因此可以显著降低乱序执行硬件的功耗(如将大量数据转移则会产生较大的功耗),以及处理器核心面积。而核心面积的精简则为Sandy Bridge提升AVX指令集运算性能创造了条件。

物理寄存器堆的使用为降低功耗、提高乱序执行引擎缓存创造了条件。
我们知道,AVX指令集将计算位宽由128-bit提升到256-bit,一次计算就可以处理更多的数据。但要实现AVX指令集则需要处理器硬件上的配合。得益于物理寄存器堆的使用,Sandy Bridge处理器可以将更多的晶体管用在关键的运算单元里,其中所有的SIMD浮点运算单元计算位宽由传统处理器的128-bit升级到256-bit。同时,由于浮点运算单元吞吐量的增大,乱序执行引擎也采用了更大的缓存空间予以配合。此外,Sandy Bridge的整数执行单元也有一定改进,如ADC指令吞吐量翻番、乘法运算加速25%。
2.颠覆内部结构 环形总线显威力
在Nehalem/Westmere等现有Intel处理器中,每个核心都与三级缓存单独相连,各自需要大约1000条连线,这种情况下如果频繁访问三级缓存,就可能出现问题。而对于整合了GPU图形核心、视频转码引擎的Sandy Bridge来说,如果沿用这样的做法还得再增加多达2000条连线。为此Sandy Bridge引入了早在Nehalem EX与Westmere EX服务器处理器上使用的环形总线(Ring Bus),每个核心、每一区块三级缓存(LLC)、集成图形核心、媒体引擎、系统助手(即处理器北桥功能部分)在这条总线上都拥有自己的接入点,形象地说就是多个“停靠站台”。
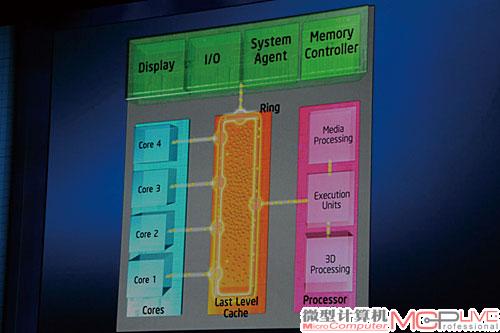
环形总线带来的大好处是让每一个功能部分都可随时访问三级缓存,降低延迟,并提升数据吞吐带宽。
采用环形总线的大好处是可以降低每个核心访问三级缓存的延迟,并提升三级缓存的数据吞吐带宽。Intel现有处理器的每个核心要访问三级缓存时,都必须通过一条缓存流水线发出请求,经过优先级排序后才能依次访问。而在Sandy Bridge中,则将三级缓存划分成多个区块,并分别对应每一个CPU核心。因此每个核心都可以随时访问全部三级缓存,其延迟从36个周期减少到26~31个周期。同时,Sandy Bridge每个核心与三级缓存间的数据带宽为96GB/s,因此四核心Sandy Bridge的三级带宽可以达到惊人的96GB/s×4=384GB/s。
此外三级缓存的频率也开始和处理器核心频率同步,因而速度更快,缺点就是三级缓存也会随着处理器核心降频而降频。所以如果处理器降频的时候,图形核心又正好需要访问三级缓存,那么低速的三级缓存就会影响图形核心的性能。

